Big Data Dictionary
Cassandra
Cassandra is presented as highly scalable, eventually consistent, distributed, structured key-value store. Cassandra brings together the distributed systems technologies from Dynamo and the data model from Google's BigTable. Like Dynamo, Cassandra is eventually consistent. Like HBase, Cassandra provides a ColumnFamily-based data model richer than typical key/value systems. In Cassandra's data model, column is the lowest/smallest increment of data. It's a tuple (triplet) that contains a name, a value and a timestamp. A column family is a container for columns, analogous to the table in a relational system. It contains multiple columns, each of which has a name, value, and a timestamp, and are referenced by row keys. A keyspace is the fi rst dimension of the Cassandra hash, and is the container for column families. Keyspaces are of roughly the same granularity as a schema or database (i.e. a logical collection of tables) in RDBMS. They can be seen as a namespace for ColumnFamilies and is typically allocated as one per application. SuperColumns represent columns that themselves have subcolumns (e.g. Maps). The figure below illustrates the data model of Cassandra's data store.
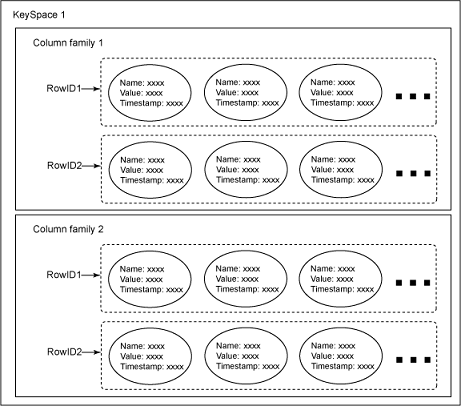
Like Dynamo, Cassandra provides a tunable consistency models which allows to choose the consistency level that is suitable for a speci c application. For example, it allows to choose how many acknowledgments are required to be receive from di erent replicas before considering a WRITE operation to be successful. Similarly, the application can choose how many successful response need to be received in the case of READ before return the result to the client.