Big Data Dictionary
iMapReduce
In the MapReduce framework, each map or reduce task contains its portion of the input data and the task runs by performing the map/reduce function on its input data records where the life cycle of the task ends when nishing the processing of all the input data records has been completed. The iMapReduce framework supports the feature of iterative processing by keeping alive each map and reduce task during the whole iterative process. In particular, when all of the input data of a persistent task are parsed and processed, the task becomes dormant, waiting for the new updated input data. For a map task, it waits for the results from the reduce tasks and is activated to work on the new input records when the required data from the reduce tasks arrive. For the reduce tasks, they wait for the map tasks' output and are activated synchronously as in MapReduce. The below figure compares between the data flow of the standard MapReduce framework and the iMapReuce framework.
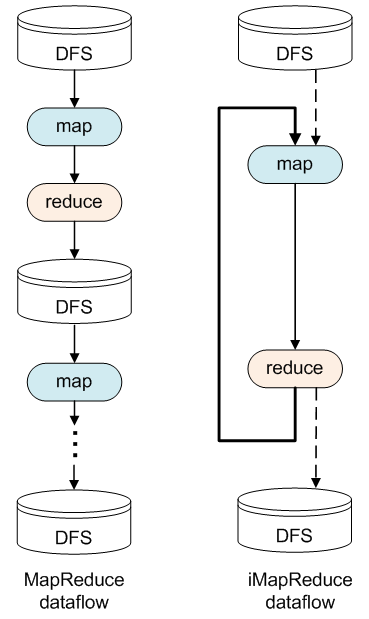
In the iMapReuce framework, jobs can terminate their iterative process in one of two ways:
- Defi ning fixed number of iterations: Iterative algorithm stops after it iterates n times.
- Bounding the distance between two consecutive iterations: Iterative algorithm stops when the distance is less than a threshold.
The iMapReduce runtime system does the termination check after each iteration. To terminate the iterations by a fi xed number of iterations, the persistent map/reduce task records its iteration number and terminates itself when the number exceeds a threshold. To bound the distance between the output from two consecutive iterations, the reduce tasks can save the output from two consecutive iterations and compute the distance. If the termination condition is satis ed, the master will notify all the map and reduce tasks to terminate their execution.