Developing a Clojure Edge
State and Time
Variables are places, memory locations. Values do not change. Numbers, strings, even structured data and facts in time. We observe the world as a stream of values. The values themselves do not change, but we make new associations over time. To make coherent decisions we need to process snapshots in time. It is easier to reason about values than places in memory.
Concurrency (sync vs locking)
parallelization for free (pmap)
immutable is the default.
Modifying vars requires some additional ceremony
Clojure has a strong notion of values
Place oriented vs Value oriented
Software Transactional Memory model
refs
Alternatives
atoms
actors
Watchers
Facts have time
Concurrency
(def foo (ref 1))
(dosync (alter foo inc))
=> 1
@foo
=> 1
Done in a transaction. Functions must be side-effect-free as there will be retries.
(def foo (agent 1))
(send foo inc)
(await foo)
@foo
=> 1
send-off uses a different threadpool which is suitable for blocking operations. Imagine if you had a limited threadpool that was taken up with blocking operations. Conversely imagine if you started a new thread for every operation. The distinction is useful for managing the amount of active threads.
Agents are asynchoronous.
Atoms are my favourite because they are the simplest of all, providing atomic updates as the only guarantee.
(def foo (atom 1))
(swap! foo inc)
=> 1
@foo
=> 1
Visualization
Visualization is key to correct software. It is not enough to process your data, you should alway plot it also. For plotting use Incanter. For our drone control program however we will be displaying a 2D map of the locations of drones, hospitals and remotes. For this we will use the quil library. This is very typical of Clojure development, there are many high quality libraries that provide a DSL style interface for manipulating underlying java libraries, in this case the Processing library. We are able to describe the shapes, colors and text we wish to be displayed to render a hospital like so:
(defn draw-hospital [{[x y] :location}]
(with-translation [x y]
(text "hospital" 0 -10)
(stroke 255)
(stroke-weight 5)
(fill 255)
(ellipse 0 0 30 30)
(stroke 128 0 0)
(fill 128 0 0)
(rect 0 0 25 5)
(rect 0 0 5 25)))
Note the use of destructuring in the arguments list, we could have written this as
(defn draw-hospital [h] …)
But then we would have to extract the fields we want like in the below example:
(defn draw [world]
(background-float 200)
(doseq [h (world :hospitals)]
(draw-hospital h))
(doseq [r (world :remotes)]
(draw-remote r))
(doseq [d (world :drones)]
(draw-drone d)))
The end result is that we can see where our drones are and what they are doing:
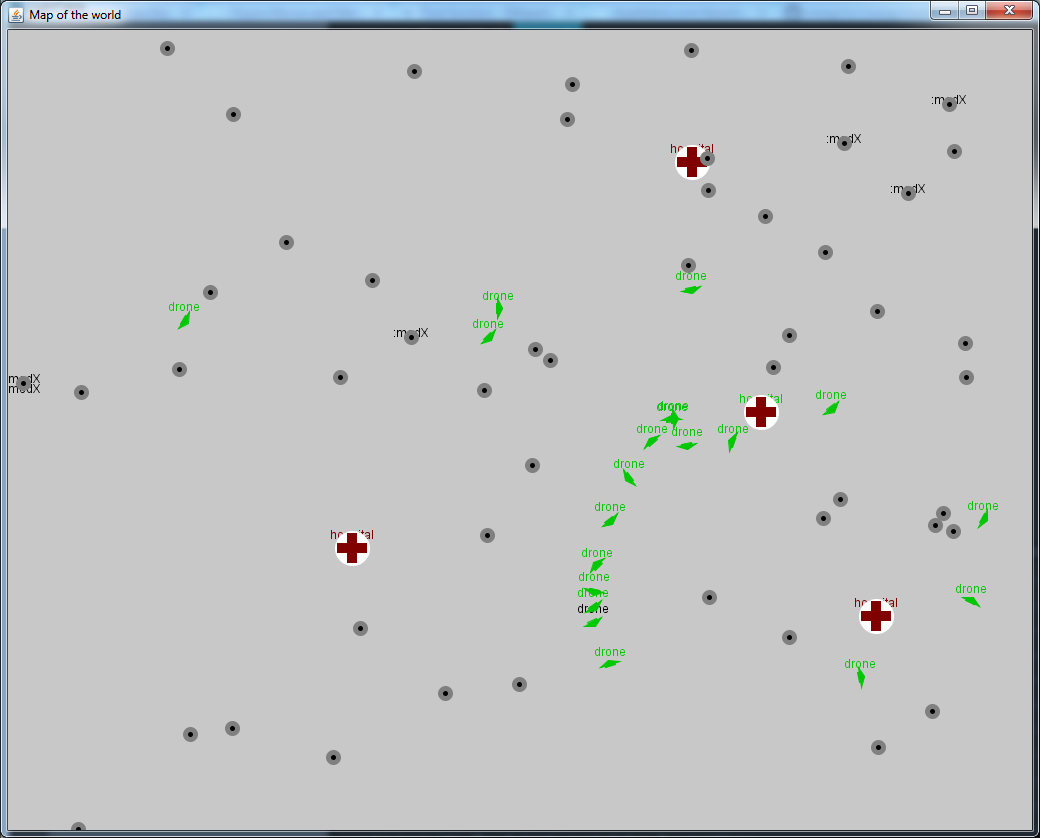
Visualization is important not just for the end product but also something you should strive for throughout your code and development. Visualization and modularization go hand in hand. As you develop portions of your code, try to visualize the output. This can be as straightforward as writing tests and examples to confirm that functions are behaving as you expect them to.
For basic visualization (printing) keep in mind pprint, which does pretty printing. Reading maps especially is far easier when they are formatted by pprint.
(clojure.pprint/pprint (zipmap [:a :b :c :d :e :f]
(repeatedly rand)))
=>
{:f 0.3050567969621705,
:e 0.628327751914002,
:d 0.051675386183382854,
:c 0.01415356720668115,
:b 0.4055346212074916,
:a 0.7316911656692383}
One annoying feature is that pprint by default prints to the console. If you want to use it to create a string, you can capture it using with-out-str which binds *out* to a fresh StringWriter and returns the String:
(with-out-str (clojure.pprint/pprint {:a 1 :b 2}))
=> "{:a 1, :b 2}\r\n"
Storage
slurp and spit
(spit "test.txt" "some text that we wrote to a file")
(slurp "test.txt")
with-open ensures that the bound reader/writer is closed
(io! (with-open [w (writer state-file)]
(clojure.pprint/pprint world w))
Applies to anything that should call .close
io! lets the compiler detect when you try to use side-effects in a transaction.
Warning: laziness does not work well with with-open.
It is possible to create a lazy sequence that reads from a file… but if you create the lazy sequence inside a with-open, the file will be closed. Because the sequence is not realized until after the code exits that section, when you evaluate the lazy sequence it will fail because the file is closed.
edn-read
(clojure.edn/read state-reader)
The semantics we want are durability, debugging, replay, serialized updates
Event sourcing.
Create command functions that check the validity of an update and raise an event. Define transformation functions that transition the world to a new state. Create a pipeline for raised events to be saved to disk, applied to the domain model, and published. Create helpers to hydrate snapshots of state and process event logs to recreate state.
The Event Sourcing pattern is to save every change that is made to your domain model. You can reconstruct the domain model by replaying all the events. To do this effectively requires discipline. Every change to your domain model must be done with commands that raise events. Commands validate that the caller is producing a valid update, and produce an event which represents the update. The event is sent to a pipeline that stores, publishes, and applies the update to the domain model.
Commands and events
A command validates whether an update can be done, and if so, gathers up all the information required to perform the update, and raises this information as an event. In Clojure we represent data in hashmaps in preference to defining structures or objects, so my events will be hashmaps that have the data required to perform the desired transform.
(defn delete-thing-command [id]
(when (and authorized (@world id))
(raise! :delete-thing {:thing-id id})))
Commands look so straightforward that you might be tempted to forget about them and just call raise where you need it. I prefer to keep all the event processing and commands in pairs together in the same namespace for easy comparison, as the event processing method will be expecting matching fields in the event.
Defining the update itself is the important part. For every event type we define a transformation function of the current domain state into a new domain state. Instead of having the command call the event processor directly, we hand the event off to a pipeline. The pipeline needs to know how to dispatch the function to call by event type.
Multi-methods
Polymorphic dispatch can be done with multimethods. We define a signature for accepting a world and an event. Implementations of accept will perform a data transform, returning a new world. Raising events will call accept which will dispatch to the appropriate implementation. When defining the signature of a multimethod we provide a function that returns the :event property from an event hashmap (which will be the event type):
(defmulti accept
(fn [world event] (:event event)))
Implementing event handlers is a matter of conforming to the signature and providing the event type that it is appropriate for:
(defmethod accept :delete-thing
[world event]
(dissoc world (event :thing-id)))
When an event is raised it goes through a pipeline which will call accept. That pipeline is where we may make implementation decisions about how and where we want to store data. If we only consider the command/event/transform pattern, there is very little code overhead to conform to this pattern in Clojure.
The trade off is conforming to a command/event/transform pattern in exchange for durability, debugging, logging, history, storage flexibility, arbitrary denormalization, and read separation. In my experience, the catch is that implementing the pattern in C# is tricky. Assuming you get that part right or use a good library you are still stuck with type fatigue.
Clojure elides many implementation pain points:
-
passing around an immutable world is safe and convenient
-
multimethod dispatch is expressive
-
data format matches memory model (edn)
-
philosophical alignment (transform functions, deep nesting, hashmaps and vectors)
The event pipeline
Raising an event is primarily storing it and calling accept to apply the changes to the domain model:
(let [o (Object.)]
(defn raise! [event-type event]
(locking o
(let [event (assoc event
:event event-type
:when (java.util.Date.)
:seq (swap! event-count inc))]
(store event)
(publish event)
(swap! world accept event))))))
I like to mix in some metadata with the event: when it happened and a sequence number. The event-type is mandatory for dispatch. Clojure does allow you to specify metadata separately, so you can do that if you prefer.
I choose to use an atom to store the domain model in. The semantic I want is one synchronous writer of state. An agent is almost perfect for this except that quite often you want to return a result to the caller indicating success or failure, whereas agents are send and forget. To ensure all events are raised synchronously I use plain old locking on a private object. Your domain semantics might require commands to be processed synchronously for validating against the domain.
We have many options available for storage, but for now we will use the straightforward file based approach:
(defn- store [event]
(let [event-file (file "data" (str @current-label ".events"))]
(io! (with-open [w (writer event-file :append true)]
(clojure.pprint/pprint event w)))
(when (>= (event :seq) events-per-snapshot)
(snapshot @world))))
I append to an events file and write the event data structure using Clojure’s data format. The file has the same base name as the current snapshot.
Storing history is powerful. If you want to mine your data by reprocessing events and calculating some new views, you have all the data to do so. You are not limited to the domain state.
Publish is a way to define additional functions to be called on each event. One obvious use is to send out notifications to clients of relevant events. Another use is when you want to maintain separate models. For example your domain logic may not care about statistics but you might want to build up a view of statistics by processing events as they happen in a separate model. If you have a high traffic website, you might want to have several read servers. You can feed these read servers the events and they can perform denormalization of those events into their local read model (this pattern is called Command Query Responsibility Segregation).
Rebuilding the domain
Rehydrating the domain model is a matter of replaying all the events that were stored. We specify which state file to load as the initial model, and optionally an event-id for a particular point in time:
(defn hydrate
([label] (hydrate label nil))
([label event-id]
(reset! current-label label)
(reset! event-count 0)
(io! (with-open [state-reader (data-reader label ".state")
event-reader (data-reader label ".events")]
(let [world (clojure.edn/read state-reader)
all-events (read-all event-reader)
events (if event-id
(take-while #(<= (% :id) event-id)
all-events)
all-events)]
(reduce accept world events))))))
This is convenient for testing and debugging. You can set up state files to test a scenario, or load up the domain model just prior to an error occurring to recreate an issue.
If you need to handle a very large number of events, it is convenient to take periodic snapshots of the domain model state. That way when you want to rehydrate a state you only need to process the subsequent events from the latest snapshot. Clojure data structures are immutable so we can write the snapshot asynchronously without fear of the world changing under our feet.
(defn snapshot [world]
(let [sf (java.text.SimpleDateFormat.
"yyyy_MM_dd__HH_mm_ss__SSS")
now (java.util.Date.)
label (.format sf now)
state-file (file "data" (str label ".state"))]
(reset! current-label label)
(reset! event-count 0)
(future
(io! (with-open [w (writer state-file)]
(clojure.pprint/pprint world w))))))
A new thread is spawned by future, which may take some time to complete storage if the domain model is very large. Subsequent events are written to the new label and may be written even before the snapshot completes. If a snapshot fails to write, we still have all the data and can rehydrate by going back to the previous snapshot and processing all those events and then the events with the new label.
Clojure’s multimethods, immutable data structures, readable data syntax, and data transform functions align closely with the command/event/transform pattern. To implement the pattern, define accept methods for every state transition, and commands to create valid events. Working on disk is usually convenient for experimenting. You can migrate to another infrastructure later without touching your logic. Event sourcing is a good default choice during application development when you reach the point where storage is required.