Big Data Dictionary
Hive
The Hive project is an open-source data warehousing solution which has been built by the Facebook Data Infrastructure Team on top of the Hadoop environment. The main goal of this project is to bring the familiar relational database concepts (e.g. tables, columns, partitions) and a subset of SQL to the unstructured world of Hadoop while still maintaining the extensibility and exibility that Hadoop provides. Thus, it supports all the major primitive types (e.g. integers, floats, strings) as well as complex types (e.g. maps, lists, structs).
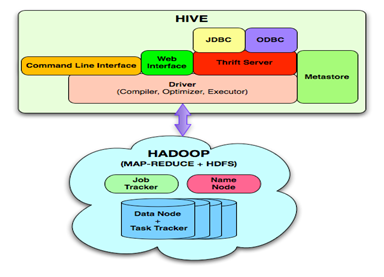
The above figure illustrates the Hive's achitecture. Hive supports queries expressed in an SQL-like declarative language, HiveQL, and therefore can be easily understood by anyone who is familiar with SQL. These queries are compiled into Hadoop jobs that are executed using Hadoop. In addition, HiveQL enables users to plug in custom MapReduce scripts into queries. HiveQL supports Data De nition Language (DDL) statements which can be used to create, drop and alter tables in a database. It allows users to load data from external sources and insert query results into Hive tables via the load and insert Data Manipulation Language (DML) statements respectively. However, HiveQL currently does not support the update and deletion of rows in existing tables (in particular, INSERT INTO, UPDATE and DELETE statements) which allows the use of very simple mechanisms to deal with concurrent read and write operations without implementing complex locking protocols. The metastore component is the Hive's system catalog which stores metadata about the underlying table. This metadata is speci ed during table creation and reused every time the table is referenced in HiveQL. The metastore distinguishes Hive as a traditional warehousing solution when compared with similar data processing systems that are built on top of Hadoop-like architectures like Pig Latin.
In general, Hive is a great interface for anyone from the relational database world, though the details of the underlying implementation aren't completely hidden. You do still have to worry about some di erences in things like the most optimal way to specify joins for best performance and some missing language features. Hive does o er the ability to plug in custom code for situations that don't fi t into SQL, as well as a lot of tools to handle input and output. Hive su ers from some limitations such as it lacks support for UPDATE or DELETE statements, INSERTing single rows, and date or time datatypes, since they are treated as strings.