Big Data Dictionary
MapReduce/Hadoop
The MapReduce framework is introduced as a simple and powerful programming model that enables easy development of scalable parallel applications to process vast amounts of data on large clusters of commodity machines. One of the main advantages of this approach is that it isolates the application from the details of running a distributed program, such as issues on data distribution, scheduling and fault tolerance. In this model, the computation takes a set of key/value pairs input and produces a set of key/value pairs as output.
The user of the MapReduce framework expresses the computation using two functions: Map and Reduce. The Map function takes an input pair and produces a set of intermediate key/value pairs. The MapReduce framework groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function. The Reduce function receives an intermediate key I with its set of values and merges them together. Typically just zero or one output value is produced per Reduce invocation. The main advantage of this model is that it allows large computations to be easily parallelized and re-executed to be used as the primary mechanism for fault tolerance.
The design of the MapReduce framework has considered the following main principles:
- Low-Cost Unreliable Commodity Hardware: Instead of using expensive, highperformance, reliable symmetric multiprocessing (SMP) or massively parallel processing (MPP) machines equipped with high-end network and storage subsystems, the MapReduce framework is designed to run on large clusters of commodity hardware. This hardware is managed and powered by opensource operating systems and utilities so that the cost is low.
- Extremely Scalable RAIN Cluster: Instead of using centralized RAID-based SAN or NAS storage systems, every MapReduce node has its own local off -the-shelf hard drives. These nodes are loosely coupled where they are placed in racks that can be connected with standard networking hardware connections. These nodes can be taken out of service with almost no impact to still-running MapReduce jobs. These clusters are called Redundant Array of Independent (and Inexpensive) Nodes (RAIN).
- Fault-Tolerant yet Easy to Administer: MapReduce jobs can run on clusters with thousands of nodes or even more. These nodes are not very reliable as at any point in time, a certain percentage of these commodity nodes or hard drives will be out of order. Hence, the MapReduce framework applies straightforward mechanisms to replicate data and launch backup tasks so as to keep still-running processes going. To handle crashed nodes, system administrators simply take crashed hardware o -line. New nodes can be plugged in at any time without much administrative hassle. There is no complicated backup, restore and recovery con gurations like the ones that can be seen in many DBMSs.
- Highly Parallel yet Abstracted: The most important contribution of the MapReduce framework is its ability to automatically support the parallelization of task executions. Hence, it allows developers to focus mainly on the problem at hand rather than worrying about the low level implementation details such as memory management, fi le allocation, parallel, multi-threaded or network programming. Moreover, MapReduce's shared-nothing architecture makes it much more scalable and ready for parallelization.
Hadoop is an open source Java library that supports data-intensive distributed applications by realizing the implementation of the MapReduce framework. It has been widely used by a large number of business companies for production purposes. On the implementation level, the Map invocations of a MapReduce job are distributed across multiple machines by automatically partitioning the input data into a set of M splits. The input splits can be processed in parallel by diff erent machines. Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a partitioning function (e.g. hash(key) mod R). The number of partitions (R) and the partitioning function are specifi ed by the user.
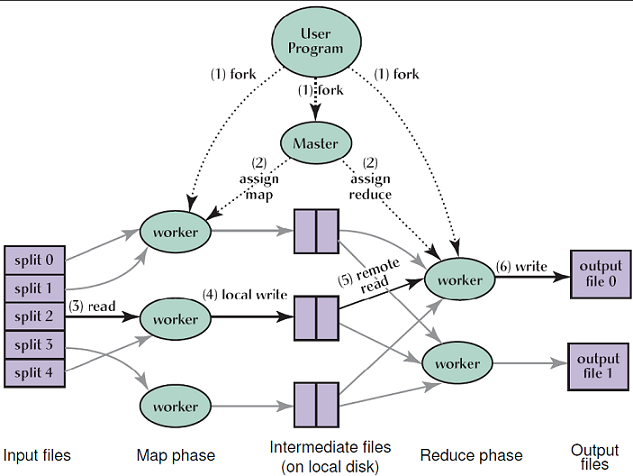
The above figure illustrates an example of the overall flow of a MapReduce operation which goes through the following sequence of actions:
- The input data of the MapReduce program is split into M pieces and starts up many instances of the program on a cluster of machines.
- One of the instances of the program is elected to be the master copy while the rest are considered as workers that are assigned their work by the master copy. In particular, there are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one or more map tasks and/or reduce tasks.
- A worker who is assigned a map task processes the contents of the corresponding input split and generates key/value pairs from the input data and passes each pair to the user-de ned Map function. The intermediate key/value pairs produced by the Map function are bu ered in memory.
- Periodically, the bu ered pairs are written to local disk and partitioned into R regions by the partitioning function. The locations of these bu ered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
- When a reduce worker is noti ed by the master about these locations, it reads the bu ered data from the local disks of the map workers which is then sorted by the intermediate keys so that all occurrences of the same key are grouped together. The sorting operation is needed because typically many di erent keys map to the same reduce task.
- The reduce worker passes the key and the corresponding set of intermediate values to the user's Reduce function. The output of the Reduce function is appended to a nal output le for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master program wakes up the user program. At this point, the MapReduce invocation in the user program returns the program control back to the user code.
The MapReduce framework is also available as an Amazon commercial service called Amazon Elastic MapReduce (Amazon EMR). Treasure Data is an add-on for Hadoop-based Big Data solution for Heroku applications.