Big Data Dictionary
Preface
In the last two decades, the continuous increase of computational power has produced an overwhelming ow of data which called for a paradigm shift in the computing architecture and large scale data processing mechanisms. In a speech given just a few weeks before he was lost at sea o the California coast in January 2007, Jim Gray, a database software pioneer and a Microsoft researcher, called the shift a "fourth paradigm". The rst three paradigms were experimental, theoretical and, more recently, computational science. Gray argued that the only way to cope with this paradigm is to develop a new generation of computing tools to manage, visualize and analyze the data ood. In general, the current computer architectures are increasingly imbalanced where the latency gap between multi-core CPUs and mechanical hard disks is growing every year which makes the challenges of data-intensive computing harder to overcome. However, this gap is not the single problem to be addressed. Recent applications that manipulate TeraBytes and PetaBytes of distributed data need to access networked environments with guaranteed Quality of Service (QoS). If the network mechanisms are neglected, the applications will just have access to a best e ort service, which is not enough to their requirements. Hence, there is a crucial need for a systematic and generic approach to tackle these problems with an architecture that can also scale into the foreseeable future. In response, Gray argued that the new trend should focus on supporting cheaper clusters of computers to manage and process all this data instead of focusing on having the biggest and fastest single computer. Unlike to previous clusters con ned in local and dedicated networks, in the current clusters connected to the Internet, the interconnection technologies play an important role, since these clusters need to work in parallel, independent of their distances, to manipulate the data sets required by the applications.
Currently, data set sizes for applications are growing at incredible pace. In fact, the advances in sensor technology, the increases in available bandwidth and the popularity of handheld devices that can be connected to the Internet have created an environment where even small scale applications need to store large data sets. A terabyte of data, once an unheard-of amount of information, is now commonplace. For example, modern high-energy physics experiments, such as DZero, typically generate more than one TeraByte of data per day. With datasets growing beyond a few hundreds of terabytes, we have no o -the-shelf solutions that they can readily use to manage and analyze these data. Thus, signi cant human and material resources were allocated to support these data-intensive operations which lead to high storage and management costs. Additionally, the recent advances in Web technology have made it easy for any user to provide and consume content of any form. For example, building a personal Web page (e.g. Google Sites), starting a blog (e.g. WordPress, Blogger, LiveJournal) and making both searchable for the public have now become a commodity. Therefore, one of the main goals of the next wave is to facilitate the job of implementing every application as a distributed, scalable and widely-accessible service on the Web. For example, it has been recently reported that the famous social network Website, Facebook, serves 570 billion page views per month, stores 3 billion new photos every month, manages 25 billion pieces of content (e.g. status updates, comments) every month and runs its services over 30K servers. Although services such as Facebook, Flickr, YouTube, and Linkedin are currently leading this approach, it becomes an ultimate goal to make it easy for everybody to achieve these goals with the minimum amount of e ort in terms of software, CPU and network.
In other scenarios, a company can generate up to petabytes of information in the course of a year: web pages, blogs, clickstreams, search indices, social media forums, instant messages, text messages, email, documents, consumer demographics, sensor data from active and passive systems, and more. By many estimates, as much as 80 percent of this data is semi-structured or unstructured. Companies are always seeking to become more nimble in their operations and more innovative with their data analysis and decision-making processes. And they are realizing that time lost in these processes can lead to missed business opportunities. The core of the big data challenge is for companies to gain the ability to analyze and understand Internet-scale information just as easily as they can now analyze and understand smaller volumes of structured information.
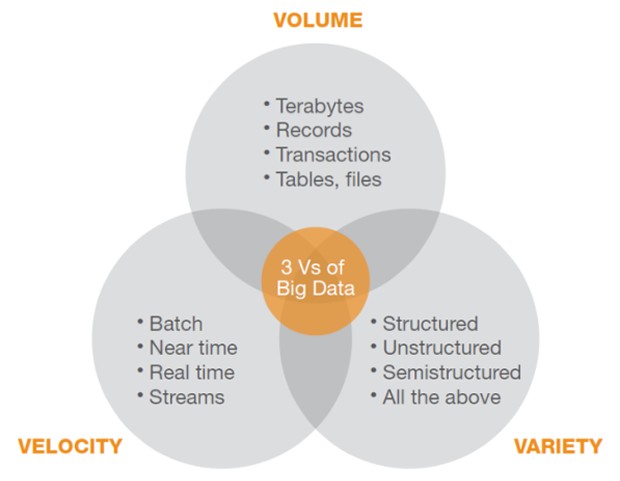
The above figure illustrates the features of the big data phonomena which is characterized by the ability of extracting insight from an immense volume, variety, and velocity of data. In this context, volume refers to the scale of data, from terabytes to zettabytes. Variety refers to the complexity of data in many different structures, ranging from relational to logs to raw text. Velocity reflects streaming data and large-volume data movements.
Book Roadmap
This book is meant to be used as your dictionary for the emerging technologies and systems in the world of Big Data Processing. The material of this book is organized in the following main sections.:
- We provide an overview of a set of basic concepts in the world of Big Data management and processing.
- We give an overview of a recently introduced wave of NoSQL systems and its suitability to support certain class of applications and end-users.
- We highlight a set of Database-as-a-Service systems that represent the new technology of hosting database systems in Cloud environment.
- We provide an overview of a set of large scale data processing systems and technologies.
- We give an overview of a set of important tools in the echo system if the Big Data management world.